


Introduction
First off I’m going to apologize for the length of this post. Over 1/3 of it covers RDC in detail, so you can skip that block if you’re not interested in the nitty gritty.
Secondly, there are some things I have had to make assumptions on for how ConfigMgr handles some of the “nitty gritty” details since they are not documented (as far as I know). I have called out these specific sections in the blog post so that you know I have had to make some educated guesses (by educated I mean that I came to the conclusions after testing theories in my lab). Please note that these educated guesses may need to be updated if I come to a different undestanding at a later date.
Continuing the series on ConfigMgr Deep Dives it’s time to clarify some misconceptions about Binary Differential Replication. I’ll be honest, they’re mostly my misconceptions. Anyone who had misconceptions about it isn’t fully to blame though - if you read the BDR docs on Microsoft Docs there is some confusing language. Language like:
“Configuration Manager supports up to five incremental versions of a content set before it resends the entire content set. After the fifth update, the next change to the content set causes the site to create a new version of the content set.”
You might assume like I did, based on those two sentences, that a content set is the entire package. This would be incorrect. You might also assume that this means every 5th package iteration leads to a redistribution of all the content of the package. This would also be incorrect. The language in the docs might be leftover language from the ConfigMgr 2007 days when Single Instance Storage was just a twinkling in the eye of the ConfigMgr team and packages were sent as a group of content.
So, what is BDR? It’s ConfigMgr’s term for Remote Differential Compression (RDC). RDC is a feature introduced with Server 2003 R2 and was originally created for DFSR. BDR is a way to reduce transfer of large files when there are binary changes to that file - think WIM files or that zipped up copy of AutoCAD that you pray to everything holy will work THIS TIME when you test the seventh revision of the content. It’s not going to provide you much benefit for that installer that has 1,000 different small files that don’t change often.
Let’s Talk About Remote Differential Compression
Since BDR is ConfigMgr’s term for RDC, it would make sense to talk about how RDC works. Just read this peer reviewed article. JUST KIDDING. Holy schnikes, that is a lot of big post-grad college words.

The VERY shorthand version of how this works is: when a client (requesting device) requests content from a server (sending device), they both generate a collection of hashes of binary data of the file (creating a signature), compare those signatures, and then the sending device sends blocks of binary data where the hashes in the signature don’t match. It looks something like this (again, incredibly simplified)
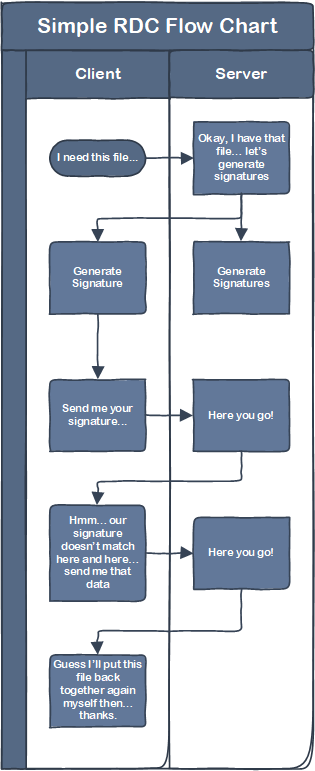
The longhand version of how this works is really cool, so I would encourage you to read this following section, but if you don’t care you can skip straight to “So How Does BDR Work?”
Brace yourself, this took me about four evenings of reading documentation to fully understand. I’m going to try to condense that learning into a handful of paragraphs here - if you’re still confused, hit me up in the comments and I’ll try to expand further.
First let’s talk about the flow of the entire request and sending process:
- Client initiates a request to the server for a file.
- Server / client both generate a signature of the file to compare, which is actually a collection of hashes of specific blocks of data in the file.
- If configured in the code, server / client both generate a signature of the signature (again, actually a collection of hashes of specific blocks of the signature file) further reducing the size of the initial signature to compare (possibly doing this a few times depending on how many layers of recursion are configured).
- IF recursive signatures are part of the code, client receives the recursive signature from the server and compares it against its recursive signature.
- IF recursive signatures are part of the code, client tells server - “these chunks of our signatures don’t match… tell me what the full content of that chunk of the original signature is.”
- IF recursive signatures are part of the code, server sends chunks of the first signature requested.
- IF recursive signatures are part of the code, client rebuilds the server’s copy of the signature by combining the chunks received with what it already has.
- Client compares its signature with the server signature.
- Client says, “I need these chunks from the file”.
- Server sends those chunks.
- Client reconstructs updated file with server provided chunks and it’s copy of the “old” file.
This is pretty much the same thing I said in the simple version, but with the addition of recursion.
Recursion is cool, but as I noted above must be coded specifically into the client/server code. Essentially RDC is reducing the size of the signature that is sent between the client and the server to further reduce bandwidth usage at the expense of a bit more CPU processing power. Frankly I have no idea how many levels (if any) of recursion ConfigMgr uses but that’s not entirely important.
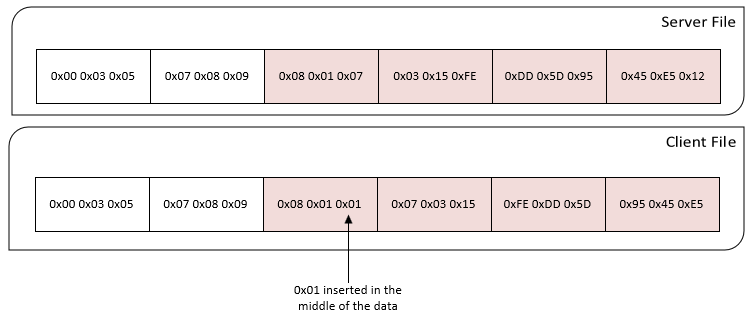
What is important is how the signature blocks are generated. You might think that it would make sense to just chunk the data into “equal” sized blocks. The problem with this method is that if you appended data at any point in the blocks, any latter blocks would also be affected. This would not be optimal. See this diagram:
This is where the magic of RDC comes into play. When the code is written to handle RDC, there are a couple parameters which get negotiated between the client and the server:
- Hash Window - the width of the window of data used to generate an H3 hash (explained later)
- Horizon - the number of consecutive H3 hashes to compare with to find a local maximum value
This is already confusing… and gets a more confusing from here on out. Essentially take the following numbers: 1,4,2,5,3,6,4,7,5,8.
Let’s define our hash window as 4. Beginning at the start of the file, we’re going to combine the data from 3 steps before 1 and 1 (making a window size of 4). Assume that anything before the beginning of the data is zero. So, our first window is “0001”. Our next window becomes “0014”, and the next “0142”, the next “1425”, the next “4253”, and so on.
Now we have our hash windows within the data, but how is the hash generated from these? Welcome to even more confusion.
First, we need to generate what is called by RDC an H3 hash of the data. We take the first byte of our window and the last byte of our window. For window 1 those would be 0 and 1 (0001). For simplicity sake let’s call these 0x00 and 0x01. We now take this data and put it through a hashing mechanism: (Hash(n-1) XOR LookupTable[0x00] XOR LookupTable[0x01], RotateBits). The reason for this weird mechanism is not important (other than trying to avoid hash collisions and improve speed). The important part is the output.
The LookupTable mentioned in that function is available here. The RotateBits value is created based on a formula using the hash window (explained here). For this post, I’ll just put the numbers in:
Since we’re on our first window, we don’t have a preceding hash value (Hash(n-1)) - RDC defines this as 0. So, we have func(0 XOR 0x5e3f7c48 XOR 0x796a0d2b, 8). We end up with a value of 0x55716327 (0x27557163 bit shifted left 8 bits). For the next step of this, we would take the output of the previous hash function and use that as the first variable in the function (e.g. 0x55716327 XOR Trailing/Left XOR Leading/Right).
Now let’s do this for the rest of the values in the file until our leading edge is the end of the file:
| Window # | Trailing (Left) Byte | Leading (Right) Byte | Output of H3 Function |
|---|---|---|---|
| 1 | 0x00 | 0x01 | 0x55716327 |
| 2 | 0x00 | 0x04 | 0x3D0DD363 |
| 3 | 0x00 | 0x02 | 0xFFE119DD |
| 4 | 0x01 | 0x05 | 0x2DE7FC94 |
| 5 | 0x04 | 0x03 | 0x82FBB42A |
| 6 | 0x02 | 0x06 | 0xFCDC7AB3 |
| 7 | 0x05 | 0x04 | 0x099B0586 |
| 8 | 0x03 | 0x07 | 0x352D0E1F |
| 9 | 0x06 | 0x05 | 0x41DB77A8 |
| 10 | 0x04 | 0x08 | 0x035A2416 |
Okay. So, what do we do with this from here? We know from before that if we were to just split the source and destination files into equal sized chunks that we might reach a place where the chunks would not match for the rest of the file (because some data was inserted) even though there might be similarity in that remaining data. So, we need a way to determine cut points for our chunks that can eventually bring us back in alignment. This is where the H3 hashes we just generated come into play and we’ll now add in the horizon.
Let’s define our horizon as 3 for simplicity sake in this example. We will look at the 3 hashes on either side of the window we are looking at. So for window 1, we compare its H3 hash to the H3 hash of 2, 3, and 4 (since there are no H3 hashes for the data before window 1). IF H3-Hash(n) (in this case Window 1) is the local maximum in this horizon, it is our chunk (block) boundary. Since it is not (0x55716327 is less than 0xFFE119DD), we move on to Window 2. Window 2 is not the maximum of 1, 3, 4, or 5, so it is not a chunk boundary. Now we reach Window 3. It IS the maximum of the windows 1,2,4,5,6 so we now define Window 3 as the beginning of the next chunk. Chunk/block 1 contains the data within windows 1 and 2.
Continuing on we see that we don’t reach another maximum within our horizon size so our 2nd chunk will be windows 3-10. In a real-world example with more data and a larger horizon size, you might find that it takes a long time to find a new chunk of data. There is a maximum limit here of 64K sized chunks to bring the chunk boundaries of the source and destination files back together quickly. If we don’t find a local maximum within 64K of the beginning of the chunk boundary, that 64K block becomes the next chunk.
Now that we have our chunks of data, we take the MD4 hash of the data within the chunk and the size of the chunk.
| Chunk # | Chunk Data | Chunk Length | MD4 |
|---|---|---|---|
| 1 | 0x01 0x04 | 2 Bytes | a5fef195412c3efd3f32fca31fbb663b |
| 2 | 0x02 0x05 0x03 0x06 0x04 0x07 0x05 0x08 | 8 Bytes | cb51f89d6e111e719317794bb08adad9 |
The combination of the chunk number, chunk length, and MD4 hash for all chunks becomes our signature.
This is done on both the server and client sides. Now let’s say for simplicity sake that what we just generated was the client side, and the server side looked like this:
| Chunk # | Chunk Data | Chunk Length | MD4 |
|---|---|---|---|
| 1 | 0x01 0x05 | 2 Bytes | 5c98fbf69db0d4b2d671a3f0bf2c262d |
| 2 | 0x02 0x05 0x03 0x06 0x04 0x07 0x05 0x08 | 8 Bytes | cb51f89d6e111e719317794bb08adad9 |
When the client compares the server signature to its copy of the signature it notices that Chunk 1 does not match but that chunk 2 does. The client now only needs request 2 bytes of the 10-byte file to make its copy of the file match the server’s copy of the file. The client can request as many chunks of data that it wants, but will only request what it needs, reducing the bandwidth necessary to transfer data drastically. So it requests chunk 1, the server sends chunk 1, and the client then reconstitutes the file from it’s source file and the data received from the server.
Now you know how RDC works.
So How Does BDR Work?
Well we now know how RDC works, but how does BDR implement RDC? You’ll remember in RDC that every time a file transfer is requested, the server and client both generate a signature of their copy of the file and the client compares the two. This could get overwhelming to the server quickly if a lot of clients were requesting the same large file and the signature had to be computed every time. ConfigMgr solves this problem by storing a copy of the signature of the file so that it doesn’t have to be recomputed for each request.
Not only does the sending site (Primary Site or CAS) keep the signature for the current copy of the file, but it ALSO keeps signatures for the current copy and four previous copies of the file - essentially the Primary Site knows what signature to expect from the receiving site server (DP) for the current and last four versions of the file. This is what I mentioned at the beginning of the post that is confusing in the documentation (at least as of 3/16/2020) - the “content set” is actually just the file that is being transferred, and all the site cares about is that the DP is within 5 versions of the latest version of the file.
Why does this matter? Assume that you have a distribution point that goes offline for two revisions of an Operating System WIM (you’ve applied two months of updates). You finally get that darn thing back up and running and it needs to grab version 7 of the WIM but it currently has version 5. **<ASSUMPTION>** The Primary Site has already decided it’s not going to generate signatures on the fly, but it still needs to know what content to send to the DP. In knowing that the DP currently has version 5 of the file, it can take its (the sending site) copy of the signature file for version 5 and use the current signature of version 7 to generate the content that needs to transfer to the DP.
If the receiving site server is outside of that window - instead of forcing it to re-signature the file the sending site just says, “You know what? I’m just gonna send you the whole file again.” **</ASSUMPTION>** Obviously, this is something to be aware of for large files like WIM files or that AutoCAD ZIP file you made. However, since this is on a PER FILE BASIS you don’t have to worry as much when it comes to files inside a package. Consider an update package. While the package itself might contain 30GB of updates, if a DP gets way out of sync with the package version, the only thing that will be sent in its entirety is the NEW content, and any content that has changed more than 5 times. Other than that, you’ll only get the small binary changes of the other files (if there are any).
Now you might be asking - but what if the copy of a file on the DP gets corrupted and the primary site sends just the bits necessary to bring the file up to the latest version? Never fear! There is still a hash validation check on the file to make sure that it matches, and the distribution of content will fail. On the next retry of content delivery, the sending site will just send all the content again to bring it back in line.
One additional thing to note, Pull-DPs (Pull Distribution Points) don’t support BDR. So if you’ve enabled Pull-DPs on a server that you use for imaging, know that BDR won’t do anything here and the entire WIM file is going to be synced (or that godforsaken AutoCAD ZIP file).
What Do I Need to Know?
This post is excessively long already - and that’s after going through a few revisions trying to pare it down. Here’s what you need to know:
- Binary Differential Replication (BDR) uses components of Remote Differential Replication (RDC) but implements it in a way that reduces the amount of processing overhead necessary on both the sending server and the receiving server.
- BDR is on a PER FILE BASIS with Single Instance Storage (SiS). It is not based on the package, even though it is enabled at the package level (or automatically if we’re talking about the application model).
- If you’re updating a package 6 times but none of the files change, or if the files change but the DP is still within 5 revisions of the changed file, the site is NOT going to send the entirety of the package again. Even if a file in the package happens to be outside of 5 revisions of the server’s copy, it will not resend the entire package, just that file. The “content set” as described in the docs is actually at the file level (due to Single Instance Storage), so unless the receiving site server is out of date 6 versions of the file, you’ll still get the benefit of BDR.
- BDR only really benefits your site when it comes to large files like WIMs. Unless you have a package where you had a lot (thousands) of small files (500k - 1MB let’s say) that change frequently, you’re probably not going to really benefit from enabling BDR on the package.
Final Thoughts
Now that I personally have a better understanding of how BDR actually works, I plan to send a pull request to update the ConfigMgr documentation to make it a bit clearer. I very much encourage you to do the same when you read the docs and find even things like typos. The Microsoft Endpoint Management team does an awesome job with these docs, but even the best can make mistakes from time to time.
Hopefully you have gained a better understanding about BDR, and until next time Happy Admining (and happy Microsoft doc updating)!
Share this post
Twitter
Facebook
Reddit
LinkedIn
Email