


It’s been a bit of time since my last post due to working on a rather large migration project. As part of this project we’re looking to utilize peer to peer content sharing features like BranchCache and Peer Cache since the client has numerous remote locations that are too small to warrant their own distribution point but also have limited bandwidth so we can’t have every client reaching out to the distribution point at the same time.
This is going to be sort of a two part post. In reality I mean that I’m using this post to tee up a big project that I’ve been working on to help support Peer Cache Source lifecycle management. Although with some of the newer features of Peer Cache that script might become a relic before it ever sees the light of day! Sucks for me - but ultimately means an easier life for all of you, so there is a silver lining to it all.
Tip 1: Roaming Devices Do Not Make Good Peer Cache Sources?

We’ll start with what seems like an obvious one. Prior to ConfigMgr 1806, client location within a boundary group was updated during heartbeat discovery. So when does heartbeat discovery run? Let’s take a look at the default configuration, annnnnnnd it’s 7 days.

So it totally makes sense that you’d never want to include a device which changes boundary groups frequently (say a laptop switching between an office and the VPN when the user arrives home) to be a Peer Cache source. If ConfigMgr believes the device belongs to a boundary group that it does not actually belong to, then now you’re likely traversing the WAN twice to deliver that content… double the trouble that you were in previously.
HOWEVER the shining light to all of this is that beginning in ConfigMgr 1806 this all changed! Fast Channel communication FOR THE WIN! When a client performs it’s keep-alive check in via Fast Channel (every 15 minutes) it also updates it’s boundary group. So if a device changes location within approximately 15 minutes of that location change ConfigMgr now knows the client resides in a different boundary (and possibly a different boundary group).
The Tip
If you so desire you could now include roaming devices as Peer Cache sources. The caveat to this tip is if the device is in low battery mode, it won’t serve up peer cached content to other devices in the boundary group. Also, you might not want to serve content over your WLAN - but with speeds as good as they are today, that might not be as big of a consideration. Consider how your roaming devices are used and whether or not you still think they’d be good fits as Peer Cache sources.
Tip 2: BranchCache Everything… Peer Cache Source Some.
So, since roaming devices can now be Peer Cache sources with limited issues, why not just enable everyting as a Peer Cache Source?

Look, I love where your head is at, but here’s the deal: ideally your Peer Cache Sources should have adequate disk space, fast enough drives, and possibly you don’t want devices with batteries. ConfigMgr Peer Cache sources have a set of thresholds that keep a source from becoming ovewhelmed. They are, afterall, user devices right? These thresholds are:
- Max Average Disk Queue Length (over 10 and it won’t serve content)
- Max Percent Processor Time (over 80 and it won’t serve content)
- Max Connections on Client/Server (whatever the default is allowed by the OS)
- Battery Charge Status (if the battery is low it won’t serve content)
Also, there is a database impact for each device that you set up as a Peer Cache source since the content map has to be stored somewhere for your Management Point to know about it. I’m not going to say that it’s super significant for a smaller site, but for those larger environmnents the impact could be substantial. Thanks to @Phil2Pint for reminding me of this.
Additionally, prior to 1806 anything configured as a Peer Cache source that had the requested content was returned to a client - with a timeout of 7.5 minutes. So imagine a client having to cycle through a dozen machines that are offline before getting to one that was online. Yuck.
As stated earlier, this changed in 1806. Provided that you have the fast channel communication port allowed (TCP 10123), then the management point checks the Peer Cache source status before returning it as a content source to the client.
Finally, you might have other business related reasons to exclude devices - like C level executives, or devices connected over wireless. Or maybe you really just don’t like a device… I’m looking at you MININT-32S1T2D.
The Tip
Still continue to selectively choose your Peer Cache sources, but you can now be a little more aggressive about it and maybe include devices that you might not have in the past (devices which are turned off frequently or even portable devices).
Tip 3: Tricking Your Clients Into Waiting For The Peer Cache Source
So you’ve decided to scrap the distribution point at your remote location which has 15 clients, but now you need to convince your network team that you’re not going to just saturate the WAN when you deploy the latest round of Windows updates to your devices in that office. How can you be sure that your clients are not all going to reach out to the distribution point in the data center at the same time?

This requires a bit of legwork to setup properly. Essentially what you’re doing is configuring your boundary group that contains your client boundaries to have no associated distribution points - then creating a fallback relationship with a boundary group that has no boundaries associated to it but contains the distribution point(s) previously associated with the original boundary group(s).

You’re right, a diagram might help explain this a bit better.
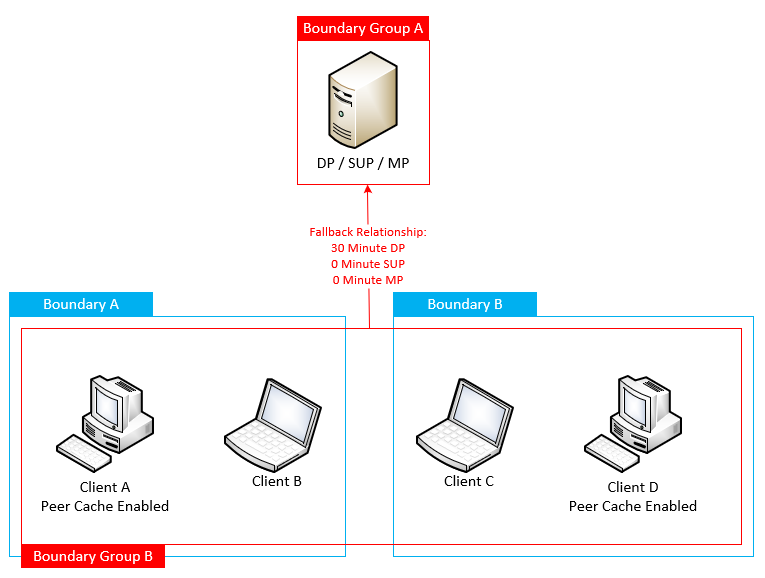
The goal here is to allow clients to fallback to their SUP / MP automatically (provided that there isn’t one local to the clients that isn’t also a DP) but wait for a specified period of time for the clients to fallback to using the DP in the fallback boundary group. The flow is someting like this:
-
Clients A, B, C, and D all request the content for Package 1. Clients B and C, since they are not Peer Cache sources, are told nothing is availble in their boundary and to wait 30 minutes before asking again (fallback time).
-
The Peer Cache Source devices (A and D) ignore the fallback timer and automatically fallback to the distribution point in boundary group A. They start downloading content and we hope that it finishes before the fallback timer for B and C doesn’t expire before all of the content is downloaded.
-
After the conifgured fallback time clients B and C check in with the Management Point again and lo and behold, now there are two sources (A and D) which have the content available locally so the clients don’t have to ask for the content over the WAN.
The Tip
Configure your boundary groups in such a way that the content is first requested by the Peer Cache sources. Utilize fallback relationships to your DPs to make this happen.
Tip 4: Sharing Content Not Installed On Peer Cache Sources
The thing about Peer Cache sources is they’re not exactly like distribution points, right? You deploy software to machines and they cache it locally, but what if you don’t want to install the software in question on the Peer Cache source, but you do want to make it available to Peer Cache clients. What if you know that a large deployment is coming up and it’s going to take more than the fallback time to download to your Peer Cache sources. You can’t just say “I want the content to be stored on this Peer Cache source”… or can you?

Here’s what you want to do. You likely have defined your Peer Cache sources into their own collection (to target the policy to enable them as such), so all you have to do is publish the package or app at the device as required - but set the required date to like December 31st, 2099 (you know kick the can down the road 80 years). When the Peer Cache source sees that it has an “upcoming” deployment (lol) it downloads the content to the cache so that it can be ready to use it when the required date and time is reached.
Pretty neat.
The Tip
When you know you have deployments coming down the road for a site, pre-deploy the content to your Peer Cache sources, even if they ultimately won’t be installing the package/application.
Final Thoughts
That about does it for this post - trying to keep them under the “10 minutes to read” mark as determined by some algorithm that I didn’t write (does it factor in my bountiful collection of memes?) In a future post we’ll take a look at managing the lifecycle of your Peer Cache sources. We’ll look at what Microsoft is doing, and we’ll take a look at a script that “intelligently” manages them per boundary group.
Until next time, Happy Admining!
Share this post
Twitter
Facebook
Reddit
LinkedIn
Email