

Conference time! MMS is upon us and it seems conferences and vacations are the only time I get some respite from the busyness of working on our Windows 10 deployment to do a little blogging. While I’m here I’ll be working on a series of posts regarding built-in variables for task sequences and how they might be of benefit to you (or how I use them in my environment). I didn’t even consider submitting a topic for MMS this year, but maybe next year I’ll take the collective learning I invest in built-in task sequence variables and propose a topic. As an aside - if you’re here at MMS and want to chat, hit me up - my schedule is available on Sched if you link up with my Twitter or LinkedIn and link your account to Sched.

Now onto business. The variable we’ll be taking a look at today is _SMSTSLastActionSucceeded. And just as the name implies it reports on whether or not the last action in the task sequence succeeded. Nothing much more to it. From TechNet :
The variable is set to true if the last action succeeded and to false if the last action failed. If the last action was skipped because the step was disabled or the associated condition evaluated to false, this variable is not reset, which means it still holds the value for the previous action.
Read on for how we use this in our environment.
So how would you make use of this or rather make it of any value in your current workflow? I was presented with a dilemma while working on the USMT portion of our Windows 10 migration task sequence. What happens when USMT fails to capture user data during a destructive process like an OS rebuild? Well in most cases you’d just set the step to not continue on failure that way you don’t lose any user data. Makes sense. ConfigMgr, what happens when USMT fails to RESTORE user data during this same destructive task sequence? I personally don’t want to go around and kick off machines to run the TS again - it wastes precious time that I could spend doing post imaging deployment steps (yeah, I wish we could automate these too… but we take a more conservative approach). For the most part all of our user data is redirected anyways (or will be by the time we roll out Windows 10 to an office) so really we’re catching the exception data at this point - data the user stored in areas which are not “approved” storage locations (root of C: drive for example).
So the solution for us came with the following requirements:
Set the step that you wish to notify on to “continue on error”:
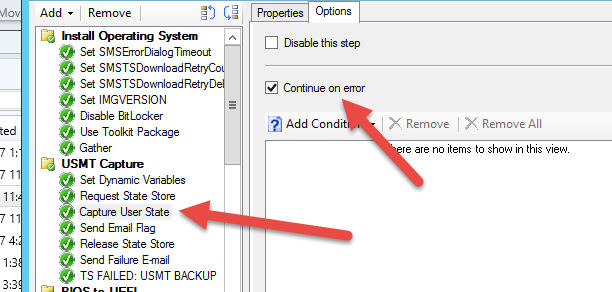
Set a variable captures the status you want to capture [fail/pass] as the VERY NEXT STEP (will be necessary to take more than one action such as e-mail and quit task sequence) by setting the options to require ‘Task Sequence Variable _SMSTSLastActionSucceeded equals “true/false”’ - you could also just set the value of the variable to _SMSTSLastActionSucceeded - I did not in this examp:
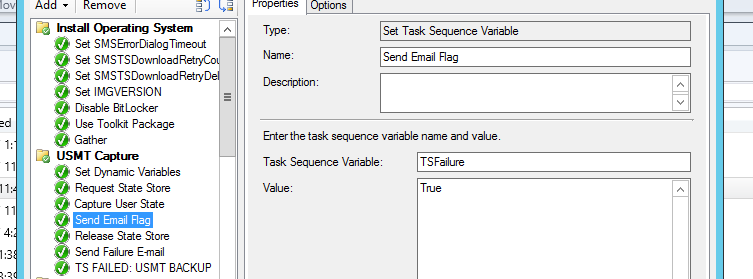
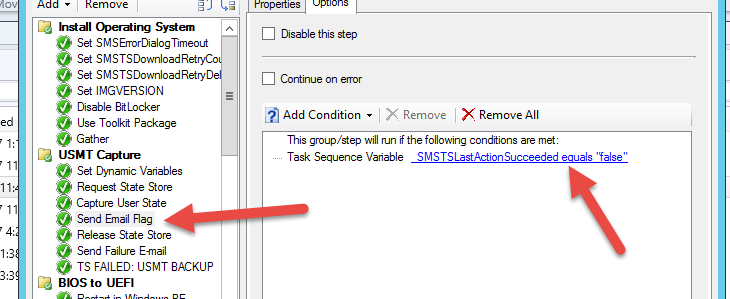
Create a notification step (you can use the script at the bottom of this post and modify to your liking if you wish) to notify you when the tracked step failed or succeeded using the variable we previously setup:
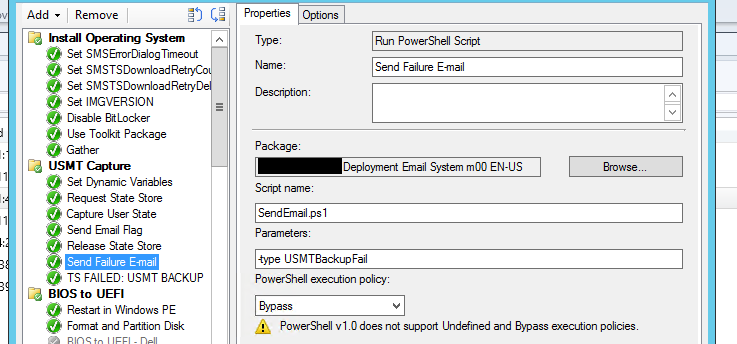
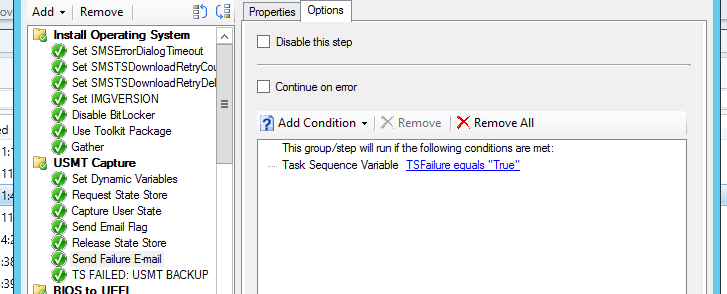
And finally, if you want to kill the task sequence, insert a “Run Command Line” step with something simple like “cmd /c echo Error” and change the success codes to 9999:
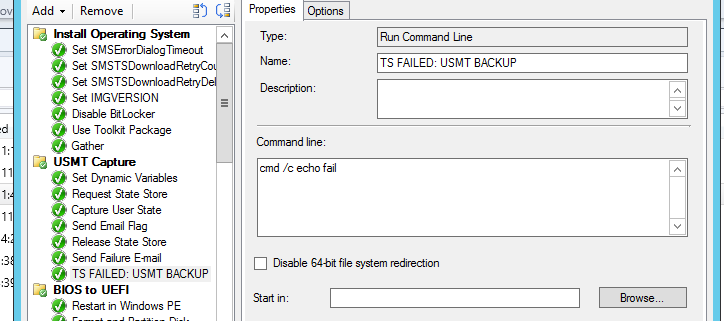
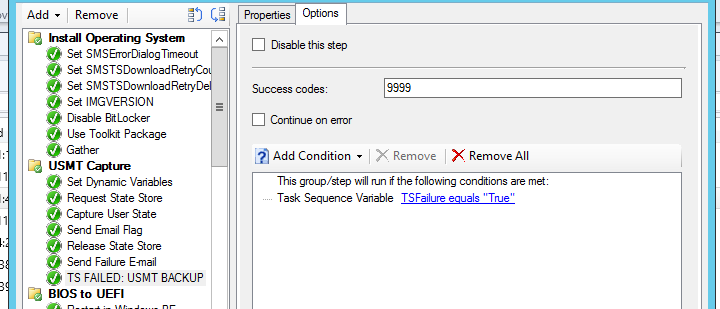
This little trick will obviously force SCCM into killing the task sequence since an echo will return a code of 0, not 9999.
That’s it! This could obviously be done on EVERY step in the task sequence if you were crazy, or just monitor a couple specific tasks that you know have an known failure rate at times. I have a suggestion for the ConfigMgr team as soon as I get some more points to make a new suggestion (something might allow you to set a variable to notify on failures - rather than monitoring the steps individually).
As promised earlier here is a link to our deployment e-mail notification script. I’m happy to answer any questions about it’s use but I won’t go into detail in this post. Hope it is helpful - and as always, happy admining!
Share this post
Twitter
Facebook
Reddit
LinkedIn
Email